Lessons from building an AI feature that works - chunking and summarization
in AI

It’s been over a year since my team at Looppanel shipped our first LLM-powered feature. We have added more such capabilities since then but the first one taught us some lessons that are worth sharing.
The feature I’m referencing - AI notes - generates high-quality notes on top of user interview transcripts. Many of our users tried out similar tools but told us over and over that our version was superior.
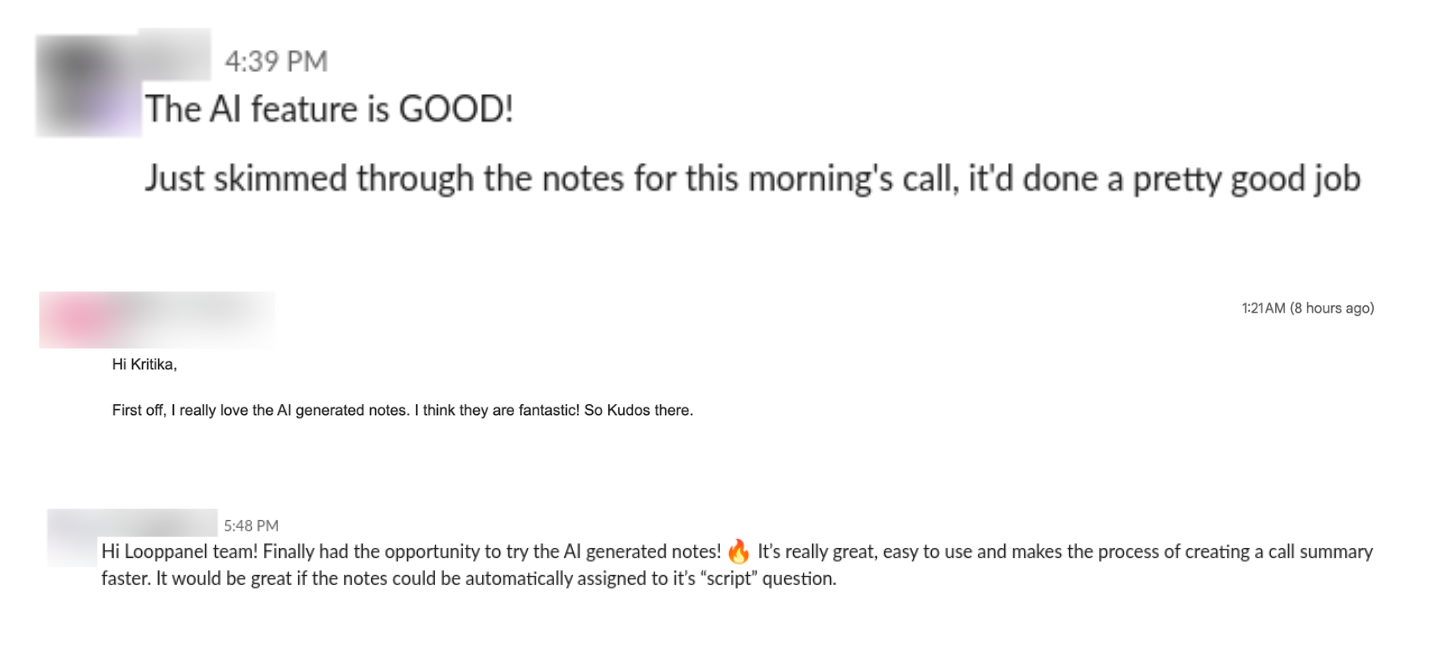
To someone who’s not analyzing user research data, these notes will not appear to be any different than those from a generic AI meeting assistant.
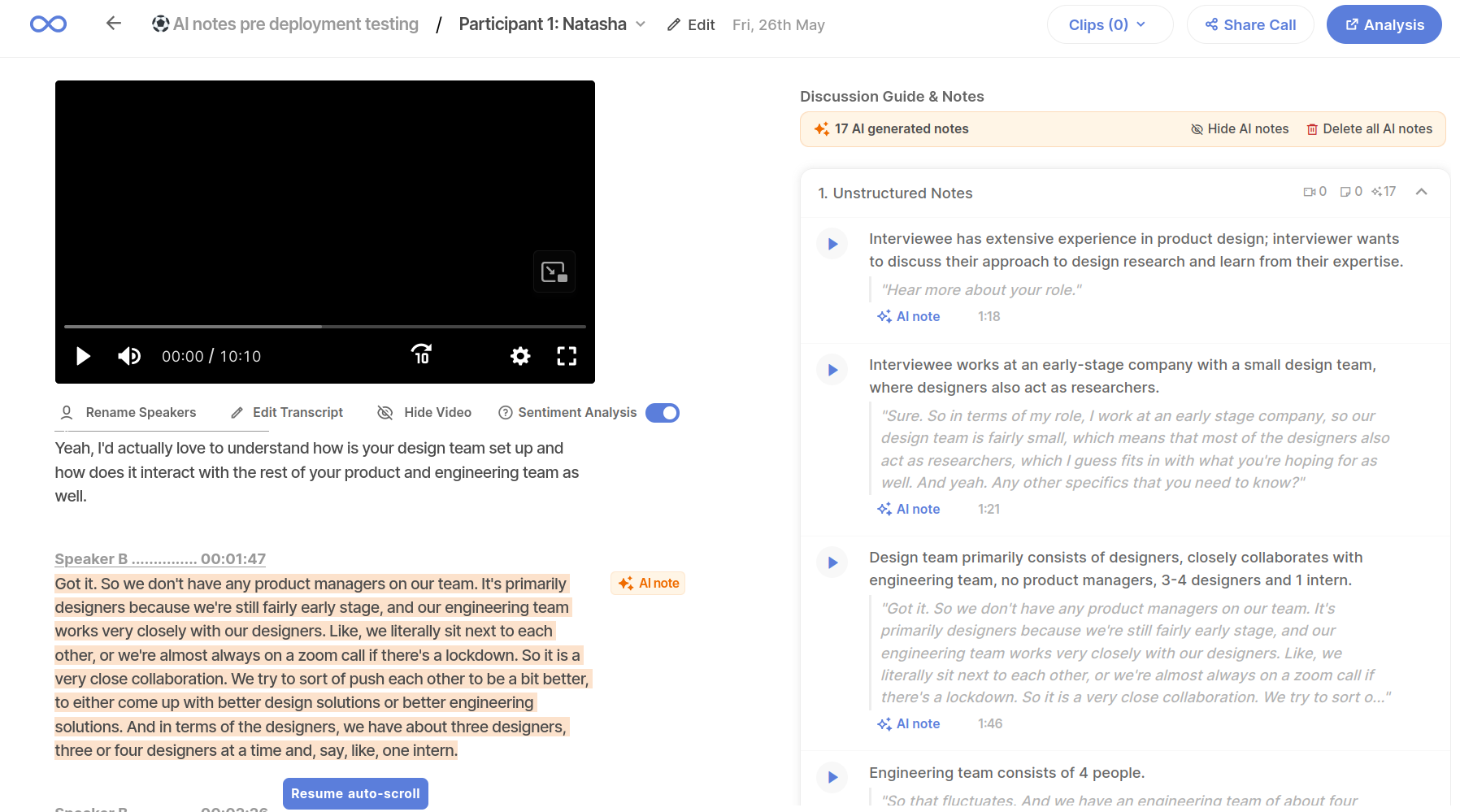
When our user looks at these notes, there are 2 aspects that they often evaluate them on - does the note capture a relevant part of the interview (chunking), and does the note describe the part correctly and objectively (summarization)? These 2 aspects are what we will dive a little deeper into.
Specifically, we will talk about 2 components of our AI notes pipeline - chunking and summarization - and lessons learnt while building them. These components also highlight how crucial data transformation/engineering and user experience (UX) are for an LLM-based feature in addition to the underlying model.
Note: please keep in mind that a lot more work went into making a successful feature in addition to the 2 components being discussed. They stand out from a technical and product POV but are only pieces of a bigger puzzle which involves user research, design and software development. In addition, I am not sharing the specific technical implementation but a high level overview and lessons. I hope that you will be able to apply them to your specific situation if relevant.
Chunking
Search for ‘chunking text for LLMs’ and you will come across many articles and documentation pages. They describe multiple methods to break down text documents into smaller parts (chunks). Chunking is mostly talked about in the context of RAG or search.
In our case, we were doing a version of text mining. We wanted to break down a user interview transcript into multiple chunks. Each chunk needed to make sense as a semantic unit in context of the entire interview. It was early 2023 and we were severely restricted by context length and semantic boundaries.
Note: 4k context length limit sounds like a distant memory compared to the 100k+ limits that have become the norm for large language models now.
Semantic chunking sounded cool as a concept but out-of-the-box implementations didn’t satisfy our use case, same as all of the other techniques on offer. For example, if you simply broke down a conversation based on number of sentences or even semantic similarity, there was a high probability that the natural flow of the conversation would not be captured. This would result in the end user spending signficant cognitive energy reviewing the chunks and the corresponding notes.
With user context and use case in mind, we wrote a chunking implementation that specifically worked for user interviews. It accounted for distinction between interviewer and interviewee speech, and identified topic changes in the conversation, to find relevant boundaries. This was an example of a domain-specific chunking methodology.
The output from this method made a lot of sense for the users and their relevance contributed to not just AI notes but multiple features that we built afterwards.
Summarization
Summaries of text documents are seen as a commodity at this point. I am fascinated by how the term can take different meanings based on the use case and who they are meant for. For us, chunking was technically challenging but generating the summary text turned out to be one of the most nuanced parts from a user experience perspective.
In addition to correctness, a user can care deeply about the tone, length, and choice of words of a summary. If you don’t get this right, the user will not care about all the fancy data engineering or modelling work you may have done until that point.

This is something we learnt after releasing a beta version. The beta users would fixate on the language of notes and ignore everything else. We iterated multiple times on relevant prompts used to create the summary by experimenting with the length, tone, etc.
In hindsight, I would’ve leveraged domain expertise earlier and a lot more to finalize the prompts used to generate the note text that a user read. That’s the approach we ended up taking for similar problem statements since then.
Wrapping up
LLMs are evolving rapidly and so is the ecosystem and user expectations around them. When building an LLM-powered product, technology can play an even bigger role than has been the norm in the last decade or so. Hence, it gets easier to ignore the user experience when working on an AI product more than usual. However, building something that actually works involves maintaining a fine balance between the technology and UX.