Understanding the state of natural language technology through a project-first approach
in AI

In early June 2020, I decided to learn about the current state of NLP and correspondingly, role of (narrow) AI. My usual approach to understanding a topic is bottom-up. Understand the fundamentals thoroughly before starting out with a project. Constrained by time and inspired by a pedagogy promoted by the likes of Fast AI, I decided to go project-first instead.
This article provides a higher-level overview of the projects and underlying motivations. You may decide to pursue or replicate this path. I may decide to write about individual pieces. For now, I present a summary of my experience and learnings.
Sidenote: From a knowledge perspective, I was already comfortable with machine learning, neural networks, the PyData stack and cloud computing. Keep that in mind if you plan on replicating this approach.
Getting started
My initial list of projects was as follows:
- Project(s) with OpenAI’s GPT-2 to better understand language models
- An ML-powered chatbot with an aim to understand NLU better
- A tool to transcript and analyze audio conversations (online or phone calls)
The list was intentionally open-ended. The plan was to do projects of interest and refine ideas along the way. The choice of exploring the GPT-2 language model was because of abundance of related learning resources and discussion. Experiments around the first two set of ideas are described below. I haven’t had a chance to start working on the third one yet.
Sidenote: A week after I had started this project, OpenAI released their API. If you are taken in by the buzz, next section may be of particular interest.
Playing around with GPT-2
GPT-2 showed up during the emergence of transformer architecture and transfer learning in NLP in 2018-19. Transfer learning is a powerful concept. It allows pretrained large neural networks (language models in this case) to be finetuned for downstream tasks. This saves practitioners the trouble of retraining entire models from scratch. This flexibility is a big reason behind language models’ success.
When starting out, I searched around for existing GPT-2 projects to replicate. That is when I stumbled upon related Python packages by Max Woolf. His work makes it easy for even absolute beginners to start out. It was then that I decided to make a parody Twitter bot as a first project.
Parody Twitter bot
A parody bot of Twitter user dril had become popular in 2019. It was powered by a GPT-2 model finetuned on dril’s tweets.
In the same spirit, I made a parody bot account that was trained on a mix of 5 different parody accounts. These included personas of Queen Elizabeth, Lord Voldemort, Darth Vader and Bored Elon Musk. To get the tweets, I used the amazing twint package.
The resultant bot account is named Queen Darth Voldemort Musk, first of their name. Yep, you read that right.
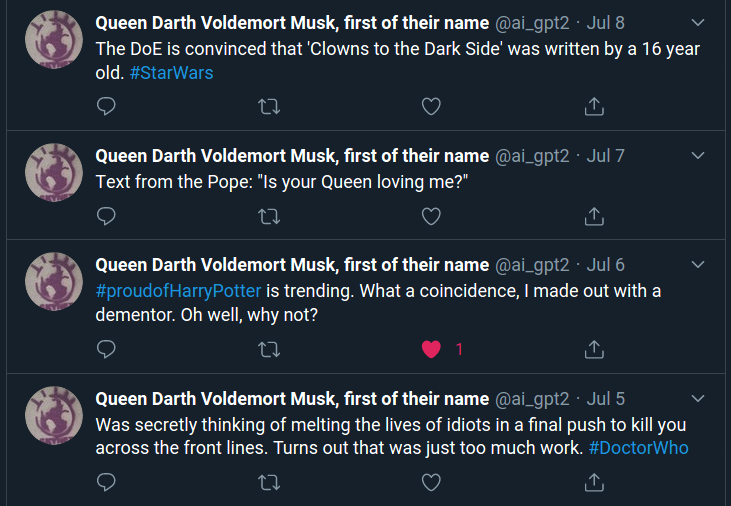
The information required to replicate this project can be found here.
Transformers, BERT and GPT-2
Then, I took a little detour to read about the theory behind GPT-2 and transfer learning in NLP. BERT is another language model that kept coming up. Both GPT and BERT are based off of the transformer architecture. However,BERT has just the encoder blocks and GPT-2 has just the decoder blocks from the transformer. That makes them more suitable for different kind of tasks.
Trying to understand the technical differences and capabilities of these two popular models is a helpful exercise. I highly recommend doing that!
Here are some relevant links around this topic:
- NLP’s ImageNet moment has arrived
- Transformers in NLP - a brief survey
- Notes on the transformer architecture
- Notes on GPT-2 and BERT
This detour also led me to my next project idea.
Evaluating NLP benchmarks
Triumphs in machine learning are tied to their performance on standard benchmarks. Even if you are not a researcher, knowing about, a benchmark such as GLUE will give you important insights about the field. If you set about contrasting BERT with GPT-2 even without in-depth expertise, looking at the benchmarks they are evaluated on will let you know the problems they are suited for. That is helpful as a practitioner.
NLP benchmarks such as GLUE and SQuAD are comprised of multiple tasks. Different tasks test for proficiency in different aspects of language such as entity recognition, question-answering and coreference resolution. In combination, they test for general language understanding.
For this project, I had two goals:
- Evaluate both BERT and GPT-2 on at least one task from relevant benchmarks
- Implement various tasks from popular benchmarks
For implementation, I used the transformers Python library by HuggingFace. I will release the associated notebook soon and hopefully write more about this subtopic.
Meanwhile, here are some helpful links:
- GLUE Explained: Understanding BERT Through Benchmarks
- Video - State of the art in NLP
- Why isn’t GPT-2 on the GLUE leadership board?
- The Big Table of (NLP) Tasks by HuggingFace
Practical NLU: conversational interfaces
Conversational interfaces are becoming increasingly prevalent. They are going to be increasingly important for consumer-facing applications. This is especially true for emerging economies where voice-first interfaces can add immense value for new internet users.
As I was thinking about conversational interfaces, I came across an online event by RASA. I attended some of the talks. They helped me get an intuition from the perspective of a developer. Post that, my inclination towards voice interfaces helped me pick my next project.
AI voice assistant
This is a great tutorial - How to build a voice assistant with open source Rasa and Mozilla tools. I simply followed it end to end.
Most of the functionalities implemented in this are available as managed services. As a matter of personal choice, I chose to start off with open source tools. There are trade-offs to be considered when thinking about a production scenario, of course.
RASA has developed a rich set of resources and an active community. They are extremely helpful.
Customer service chatbot
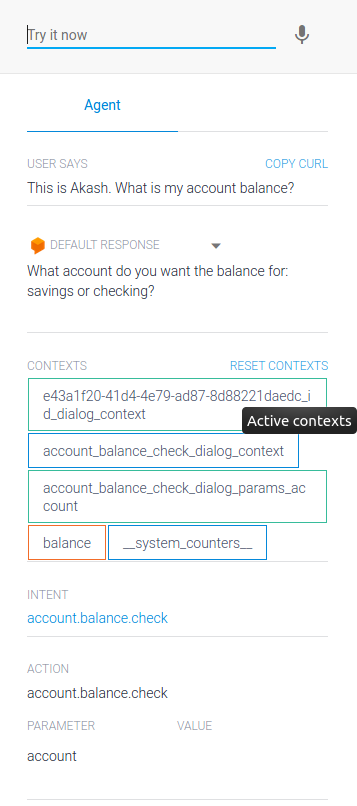
Having worked with open source tools, I wanted to try out a managed service. Options are provided by the likes of GCP, AWS, Azure and IBM. I chose to go with Google’s Dialogflow.
Once you are familiar with fundamentals such as intents and actions, it is straightforward to build a bot. The pretrained bots are a convenient feature but importing them was not a smooth experience. The one-bot-per-project feature and the lag it took for it to show up confused me for a few minutes.
Concluding thoughts
It has been an interesting experience going about the above experiments. At times, I had an itch to go deeper into topics. Choosing to let that go allowed me to explore the breadth at hand. It also let me squeeze short hacking sessions into my schedule.
There have been some exciting developments in the natural language processing field of late. In emerging economies, voice as an interface is increasingly gaining adoption. Improved machine understanding of language will also improve democratization of technology.
At the same time, we need to be realistic about its limits. Use-cases of OpenAI’s GPT-3 powered API have gone viral. So much so that their CEO, Sam Altman, made a sarcastic tweet about the hype.
RASA has laid out a concept of 5 levels of conversational AI. They also mention that we are perhaps a decade away from the fifth level.
Language has been key to humanity’s progress. Exploring it through the lens of emerging technologies is an interesting endeavour. I hope that the train of innovation will continue in a responsible manner.
If you want to have a discussion or share thoughts, feel free to reach out.
Follow the discussion on Hacker News
Source for header image: WikiMedia
{kind=link}